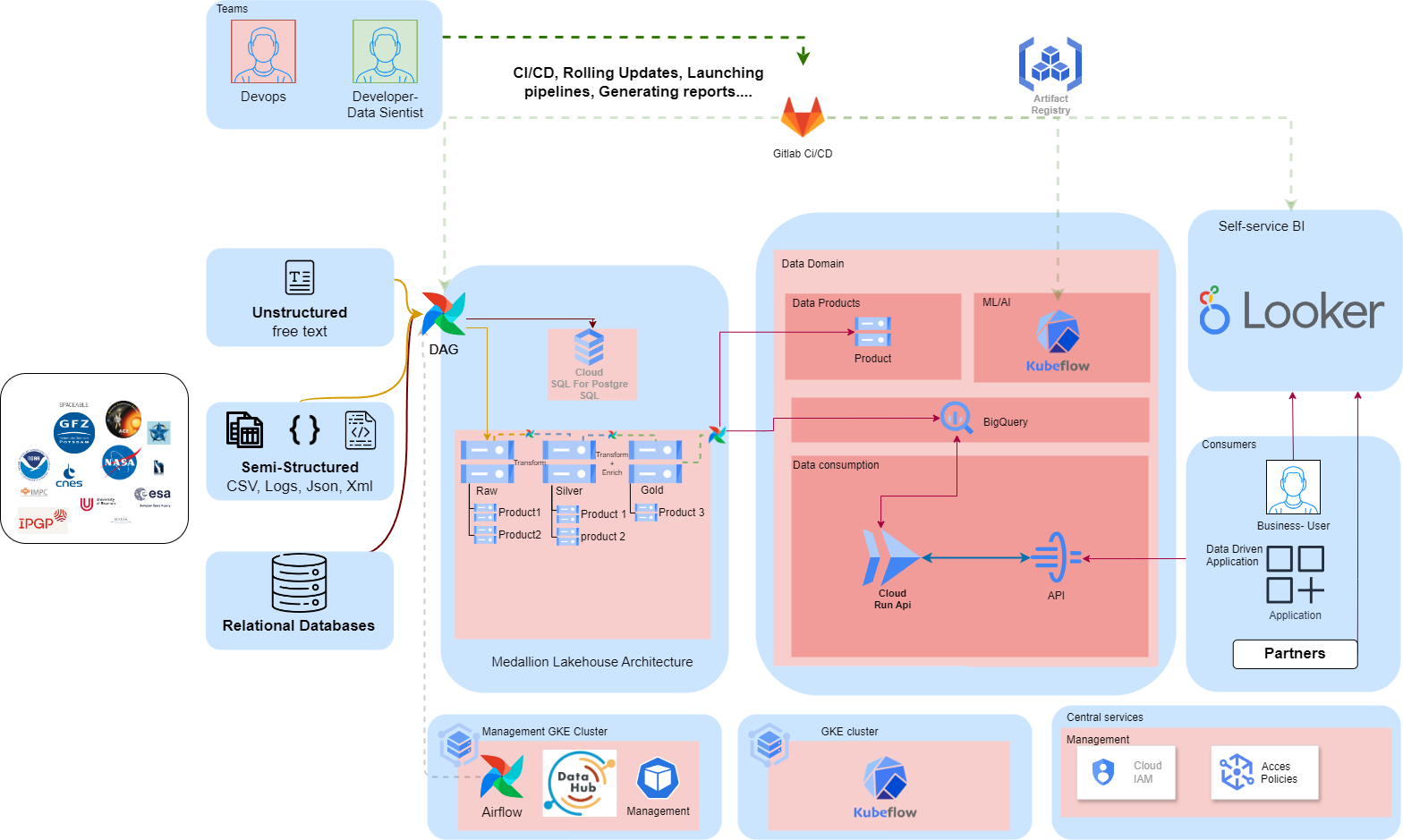
Objective
The aim of the project was to implement a Data Mesh architecture on GCP. Our main objectives included:
- Designing Data Domains and Distinct Products: Identifying and structuring independent data domains and their associated products.
- Configuring Data Sources and Destinations: Define and connect data sources to the appropriate destinations.
- Setting up ETL Pipelines: Set up pipelines for extracting, loading and transforming data using Airflow.
- Implementing a Machine Learning Pipeline: Creating an ML pipeline for the MLOps lifecycle using Kubeflow.
- Ensure Data Governance: Integrate Datahub for data governance on Cloud Storage, BigQuery and Airflow.
Platform
We chose Google Cloud Platform (GCP) for this project because of its robustness, scalability and wide range of services tailored to modern data management and machine learning needs.
Used Services
Here are the main GCP services used in this project:
- Cloud Run: for flexible deployment and management of containers.
- API Gateway: For managing APIs and ensuring service security.
- Looker: for data visualisation and advanced analysis.
- Kubeflow: For orchestrating machine learning workflows and managing the lifecycle of ML models.
- Airflow: To automate ETL workflows.
- Cloud Storage: For data storage.
- Cloud SQL: For relational databases.
- Google Kubernetes Engine (GKE): For orchestrating containers and ensuring application scalability.
- Cloud KMS: For managing encryption keys.
Conclusion
This project demonstrated our ability to implement a complex Data Mesh architecture on GCP, using a range of advanced services to meet data management and machine learning needs. Thanks to a decentralised and product-oriented approach, we were able to create a scalable and flexible infrastructure, while ensuring rigorous data governance.
Our expertise in using cutting-edge technologies and our commitment to data quality have enabled us to deliver a robust solution tailored to the demands of today’s digital landscape.