Objective
The main objective of this project was to create a robust backend application capable of :
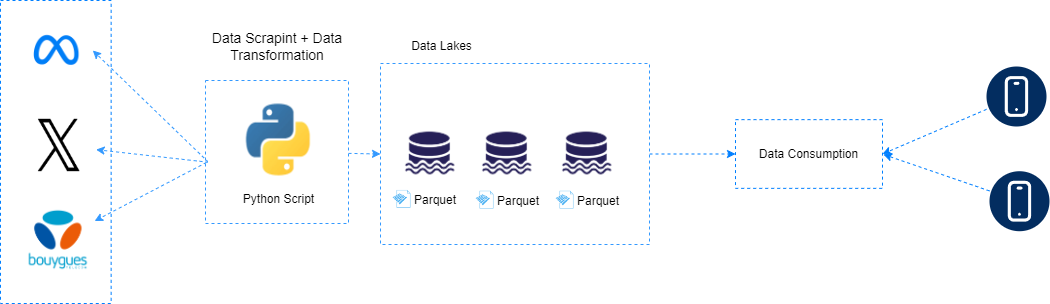
- Scrape data: retrieve data from a telecommunications website, Facebook and Twitter.
- Format data: Organise recovered data into CSV and Parquet files.
- Feed AI models: Make formatted data available to AI models to analyse trends and customer sentiments.
Platform
For this project, we used an on-premises platform to guarantee data security and control. This configuration enabled us to manage the entire data processing pipeline within our own infrastructure, ensuring compliance with data confidentiality regulations and minimising external dependencies.
Used Technologies
The choice of technology was crucial to the success of the project. We opted for Python as the main programming language because of its versatility and broad support for data manipulation libraries. Key libraries used in this project included :
- Selenium: For web scraping, in particular for interacting with dynamic web content and automating navigation tasks.
- Tweepy: A Python library for accessing the Twitter API, enabling us to efficiently retrieve tweets and associated data.
Conclusion
This project demonstrated our ability to develop a complete backend solution for scraping, formatting and making data available. Using Python and its powerful libraries such as Selenium and Tweepy, we created a pipeline that efficiently collected and processed data from a variety of sources. The formatted data is now available for AI models to analyse trends and customer sentiment, providing valuable information for businesses to make informed decisions.
Our commitment to using cutting-edge technologies and guaranteeing data integrity has enabled us to deliver a solution that meets the dynamic needs of the digital age.