Objectifs du Projet
Les principaux objectifs de ce projet étaient les suivants :
- Centraliser et unifier les données : Intégrer des données provenant de diverses sources structurées et non structurées dans une plateforme unique pour une analyse complète.
- Automatiser les processus de reporting : Créer des pipelines ETL automatisés pour transformer les données en tableaux de bord et rapports interactifs en temps réel.
Plateforme et Technologies
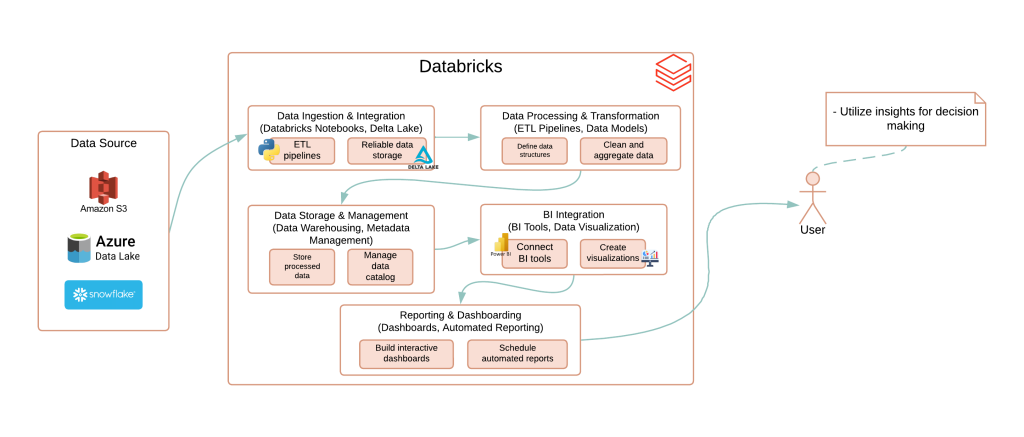
Le projet a été exécuté sur une infrastructure cloud robuste, exploitant Databricks pour le traitement distribué de grandes quantités de données et l’analyse en temps réel. Voici les principales technologies intégrées à cette solution :
- Databricks : Une plateforme basée sur Apache Spark, qui permet le traitement distribué des données volumineuses, la gestion des pipelines ETL, et favorise la collaboration entre les équipes de data.
- Delta Lake : Fournit des transactions ACID et un contrôle de version pour garantir la fiabilité et la cohérence des données tout au long des processus de transformation et de stockage.
- Azure Data Lake : Utilisé pour stocker de grandes quantités de données structurées et non structurées, offrant une solution économique et flexible pour l’entreposage des données dans le cloud.
- Amazon S3 : Une autre option de stockage dans le cloud, permettant de gérer et d’accéder aux données à grande échelle de manière sécurisée et fiable.
- Power BI / Tableau : Intégrés à Databricks, ces outils de visualisation permettent de créer des tableaux de bord interactifs et des rapports automatisés, facilitant la prise de décision basée sur des données actualisées.
- Python (Pipelines ETL) : Utilisé pour développer des pipelines ETL efficaces et automatisés, permettant de transformer, nettoyer, et charger les données de manière fluide entre les différentes sources et destinations.
Conclusion
Grâce à l’intégration de technologies avancées telles que Databricks, Delta Lake, Azure Data Lake, Amazon S3, Power BI / Tableau, et les pipelines Python, ce projet a permis de créer une solution complète et performante pour la gestion et l’analyse de grandes quantités de données en temps réel.
L’utilisation de Databricks pour le traitement distribué a optimisé l’efficacité des pipelines ETL, tandis que Delta Lake a assuré la fiabilité et la cohérence des données grâce à ses transactions ACID. Les options de stockage flexibles offertes par Azure Data Lake et Amazon S3 ont permis de gérer des volumes massifs de données, qu’elles soient structurées ou non. Enfin, l’intégration de Power BI et Tableau a facilité la création de tableaux de bord interactifs et d’analyses approfondies, fournissant des insights précieux pour une prise de décision éclairée.
En combinant ces technologies, nous avons fourni une infrastructure robuste et évolutive à nos clients, leur permettant de mieux exploiter leurs données pour répondre aux exigences changeantes de leur environnement métier.